বিসিডি (BCD)
আমরা আমাদের দৈনন্দিন হিসাব নিকাশ সবসময়ই দশমিক সংখ্যা দিয়ে করে থাকি। এই সংখ্যাকে কম্পিউটারে কিংবা ইলেকট্রনিক সার্কিট দিয়ে ডিজিটাল প্রক্রিয়া করার জন্য সেগুলোকে বাইনারিতে রূপান্তর করে নিতে হয়। কিন্তু দশমিক সংখ্যার বহুল ব্যবহারের জন্য এর দশমিক রূপটি যতটুকু সম্ভব অক্ষুণ্ণ রেখে বাইনারি সংখ্যায় রূপান্তর করার জন্য বিসিডি (BCD: Binary Coded Decimal) কোডিং পদ্ধতি গ্রহণ করা হয়েছে।

এই পদ্ধতিতে একটি দশমিক সংখ্যার প্রত্যেকটি অঙ্ককে আলাদাভাবে চারটি বাইনারি বিট দিয়ে প্রকাশ করা হয়। যদিও চার বিটে 0 থেকে 15 এই 16টি সংখ্যা প্রকাশ করা সম্ভব, কিন্তু BCD কোডে 10 থেকে 15 পর্যন্ত এই বাড়তি ছয়টি সংখ্যা কখনোই ব্যবহার করা হয় না। দশমিক 10 কে বাইনারিতে 1010 হিসেবে চার দিয়ে লেখা যায় কিন্তু বিসিডিতে 0001 0000 এই আট বিটের প্রয়োজন। নিচে BCD কোডের একটি উদাহরণ দেওয়া হলো:

উদাহরণ: 100100100110 বিসিডি কোডে লেখা একটি দশমিক সংখ্যা, সংখ্যাটি কত?
উত্তর: 100100100110 বিট গুলোকে চারটি করে বিটে ভাগ করে প্রতি চার বিটের জন্য নির্ধারিত দশমিক অঙ্কটি বসাতে হবে।

ইবিসিডিআইসি (EBCDIC)
EBCDIC (Extended Binary Coded Decimal Information Code) একটি আট বিটের কোডিং। যেহেতু এটি আট বিটের কোড, কাজেই এখানে সব মিলিয়ে 256টি ভিন্ন ভিন্ন চিহ্ন প্রকাশ করা সম্ভব। আই বি এম নামের একটি কম্পিউটার কোম্পানি তাদের কম্পিউটারে সংখ্যার সাথে সাথে অক্ষর যতিচিহ্ন ইত্যাদি ব্যবহার করার জন্য BCD এর সঙ্গে মিল রেখে এই কোডটি তৈরি করেছিল। 1963 এবং 1964 সালে কম্পিউটারে ইনপুট দেওয়ার পদ্ধতিটি ছিল- অনেক প্রাচীন কাগজের কার্ডে গর্ত করে ইনপুট দিতে হতো। কাজেই EBCDIC তৈরি করার সময় কাগজে গর্ত করার বিষয়টিও বিবেচনা করা হয়েছিল। সেই সময়ের কম্পিউটারে ইনপুট দেওয়ার জটিলতা এখন আর নেই, কাজেই EBCDIC কোডটিরও কোনো গুরুত্ব নেই।
আলফানিউমেরিক কোড (Alphanumeric Code)
কম্পিউটারে সংখ্যার সাথে সাথে নানা বর্ণ, যতিচিহ্ন, গাণিতিক চিহ্ন ইত্যাদি ব্যবহার করতে হয়। যে কোডিংয়ে সংখ্যার সাথে সাথে অক্ষর, যতিচিহ্ন, গাণিতিক চিহ্ন ইত্যাদি ব্যবহার করা যায় সেগুলোতে আলফা নিউমেরিক কোড ব্যবহার করা হয়। নিচে দুইটি বহুল ব্যবহৃত আলফা নিউমেরিক কোডের উদাহরণ দেওয়া হলো।
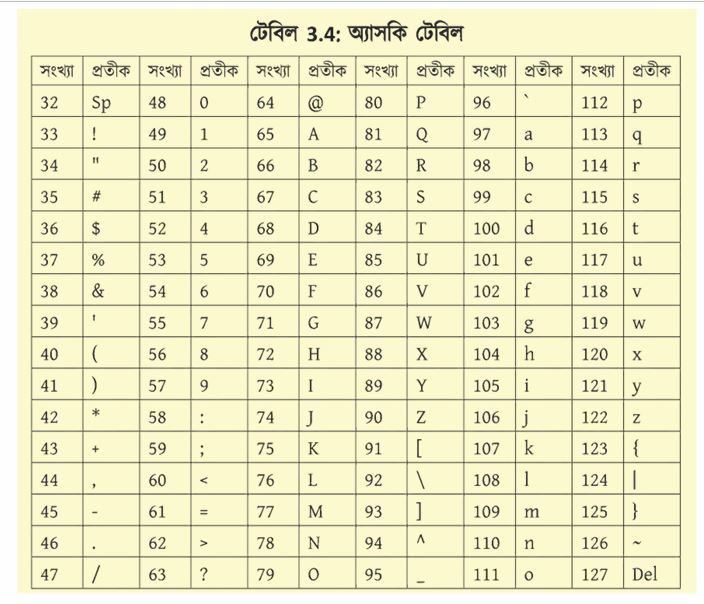
অ্যাসকি (ASCII)
ASCII হচ্ছে American Standard for Information Interchange কথাটির সংক্ষিপ্ত রূপ। এটি সাত বিটের একটি আলফানিউমেরিক কোড। এটি প্রাথমিকভাবে টেলিপ্রিন্টারে ব্যবহার করার জন্য তৈরি করা হয়েছিল এবং পরবর্তীকালে কম্পিউটার এটি সমন্বয় করা হয়। সাত বিটের কোড হওয়ার কারণে এখানে সব মিলিয়ে 128টি চিহ্ন প্রকাশ করা যায়। এর প্রথম 32টি কোড যান্ত্রিক নিয়ন্ত্রণের জন্য ব্যবহার করা হয়, বাকি 96টি কোড ছোট হাতের, বড় হাতের ইংরেজি অক্ষর, সংখ্যা, যতিচিহ্ন, গাণিতিক চিহ্ন ইত্যাদির জন্য ব্যবহার করা হয়। টেবিলে অ্যাসকি কোডটি দেখানো হলো। ইদানীং 16, 32 কিংবা 64 বিট কম্পিউটারের প্রচলনের জন্য সাত বিটের ASCII-তে সীমাবদ্ধ থাকার প্রয়োজন নেই বলে অষ্টম বিট যুক্ত করে Extended ASCII-তে আরো 128টি চিহ্ন নানাভাবে ব্যবহার হলেও প্রকৃত ASCII বলতে এখনো মূল 128টি চিহ্নকেই বোঝানো হয়। টেবিলে অ্যাসকি কোডের প্রথম 32টি যান্ত্রিক নিয়ন্ত্রণের কোড (0-31) ছাড়া পরবর্তী 96টি (32-127) প্রতীক দেখানো হয়েছে।
ইউনিকোড (Unicode)
ইউনিকোড হচ্ছে পৃথিবীর প্রায় সব ভাষার লেখালেখিকে একটি পদ্ধতিতে সমন্বিত করার কোড। ইউনিকোড কনসর্টিয়াম নামে একটি সংগঠন এটি রক্ষণাবেক্ষণ করে থাকে। 1991 সালে 24টি ভাষা নিয়ে ইউনিকোডের প্রথম সংস্করণ 1.0.0 প্রকাশিত হয় 24টি ভাষা নিয়ে যেখানে বাংলা ভাষাও ছিল। 2020 সালে ইউনিকোডের 13 সংস্করণে 154টি ভাষা স্থান পেয়েছে। 3.5 টেবিলে বাংলা ইউনিকোডের রূপটি দেখানো হয়েছে।
সর্বশেষ ইউনিকোডের Standard অনুযায়ী যেখানে প্রত্যেকটি বর্ণের জন্য 000016 থেকে শুরু করে 10FFF16 এর ভেতর একটি সংখ্যা নির্দিষ্ট করে দেওয়া আছে। উদাহরণ দেওয়ার জন্য বলা যায়, 004116 হচ্ছে ইংরেজি ‘A’ এবং 099516 হচ্ছে বাংলা অক্ষর ‘ক’। ASCII -তে 128টি (1 বাইট) বর্ণমালা সংখ্যা কিংবা যতিচিহ্ন ছিল। ইউনিকোডে প্রতিটি ভাষার জন্য চারটি বাইট পর্যন্ত (65.536) স্থান সংরক্ষণ করা আছে। সেজন্য আগে যে সমস্ত ভাষা কয়েক হাজার চিত্রকল্প দিয়ে লিখতে হতো (চীনা, জাপানি কিংবা কোরিয়ান) বলে কম্পিউটারে প্রক্রিয়া করা কঠিন ছিল, সেগুলোও এখন ইউনিকোডে সংকুলান করা গেছে। শুধু তাই নয় ইউনিকোডে প্রাচীন মিশরীয় হ্যারোলোগ্রাফিক ভাষা থেকে শুরু করে বর্তমানের ইমোজিকেও ইউনিকোডের আওতায় আনা হয়েছে।
ইউনিকোডের বাইটগুলো প্রক্রিয়া করার জন্য কয়েক ধরনের পদ্ধতি রয়েছে, তার মাঝে UTF-8 এবং UTF-16 (UTF: Unicode Transformation Format) হচ্ছে সবচেয়ে প্রচলিত পদ্ধতি। এর মাঝে ওয়েবসাইটে ব্যবহার করার জন্য UTF-8 অলিখিত Standard হয়ে দাঁড়িয়েছে কারণ যদিও প্রতি বর্ণের জন্য চার বাইট স্থান সংরক্ষণ করা আছে কিন্তু ব্যবহার করার সময় UTF-8 শুধু যে কতগুলো বিটের প্রয়োজন, ততগুলো ব্যবহার করে।